论文pdf
前言
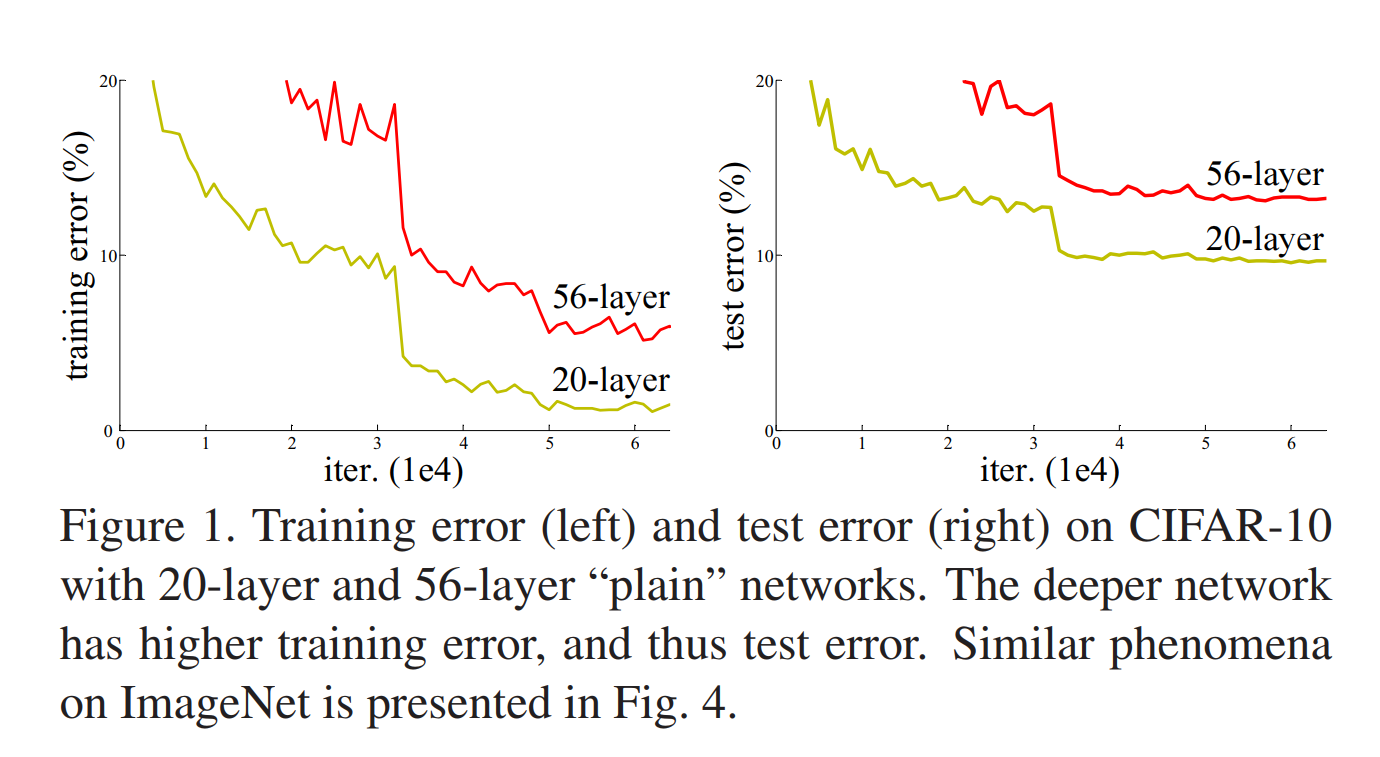
Purpose: 更深层的神经网络往往更加难以训练,而且堆叠更多的层会带来更多的问题,如梯度爆炸、梯度消失、网络退化(degradation)等。梯度爆炸、消失问题可以通过BN层与参数初始化来解决;但网络退化问题则没有很好的办法去解决。退化是指随着网络深度的增加,网络层数饱和,导致优化困难。而且训练误差与测试误差随着网络加深反而更大了,这种误差更大并不是由过拟合引起的。
Method: 作者通过一种残差结构,将输入的特征经过恒等映射输出出去来解决网络退化问题。实验结果表明残差网络更容易优化,可以通过训练更深的网络来获得更高的准确性。
Results: 使用了残差结构块的模型深度达到了152层(深度为VGG的8倍,但仍有更低的复杂度),并在ImageNet测试集上达到了3.57%的top-5错误率,取得了ILSVRC 2015分类任务的第一名。还在ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation的任务中均取得了第一名。
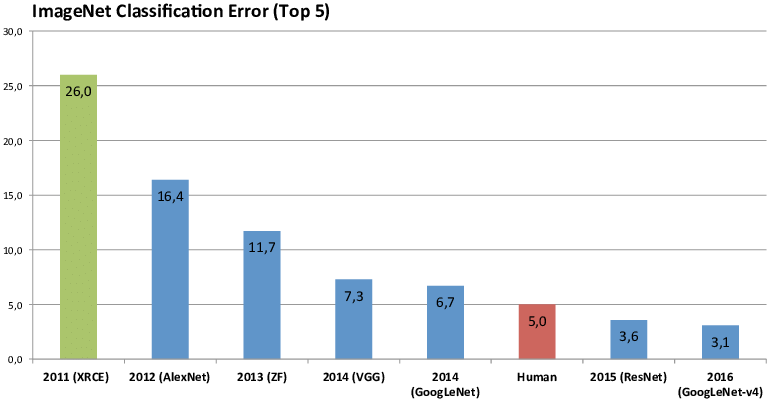
从resnet开始图像的分类任务已经做到比人还准确了,所以后面ImageNet图像分类比赛也没再举行了。
残差结构设计思路
残差表示(Residual Representations)
- VLAD是一种残差向量的字典编码表示,而Fisher Vector是VLAD的概率表示方法。它们都用于图像检索和分类的浅层表示,对于它们来说编码残差矢量比编码原始向量更有效
- 在计算机图形学中通常使用多重网格方法(Multigrid method)求解微分方程(PDE),但可以用依赖于残差向量的分层预处理来替代多重网格方法。有研究表明,使用残差向量更好优化、收敛速度更快
跨层连接(Shortcut Connections)
- 训练多层感知机时,在输入与输出之间加一层线性层
- GoogLeNet中中间层连接辅助分类器来解决梯度爆炸、消失
- Inception与highway也都用到了跨层连接
残差结构
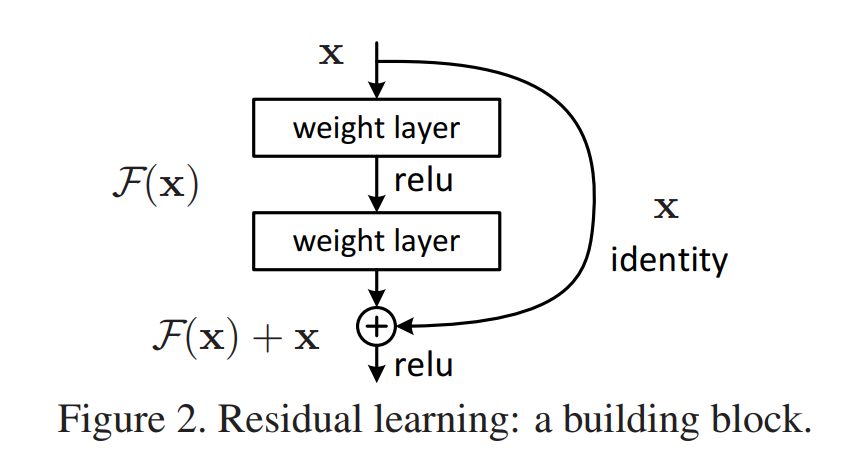
x为输入,H(x)为是我们想提取到的特征也就是输出。假设可以通过多个非线性层来逼近这个输出 H(x) 的话,同理它也可以逼近 H(x)-x 。那与其让网络学习去近似 H(x) 不如让网络去近似一个残差函数 F(x)=H(x)-x 。虽然这两种方式都能逼近我们要的输出,但网络学习的难易程度不同。
残差结构可以公式化为如下式子,F指拟合的残差映射。残差函数可以为全连接层或卷积层,层数可以随意设置(但只有一层时无明显效果)。
当F与x维度相同时,可以逐个元素相加(卷积层逐个通道在两个特征图上逐像素相加);但当维度不同时,需要给x加上一个线性映射,使它的维度与F相同。
卷积层时用1×1卷积进行维度匹配,这样又加了一层ReLU所以增加了网络的非线性拟合性。注意最后F与x相加时是先相加再用ReLU函数激活。
残差结构的特点
- 网络退化问题表明多个非线性层难以使H(x)直接逼近x,但通过恒等映射可以将参数学习为0,只通过跨层连接来逼近x。当网络不需要太深的时候,恒等映射的层就多一些,需要深一些的时候就都进行参数学习。这就实现了可控制深度,解决了网络退化问题。
- 当残差结构接近恒等映射时,网络更容易发现接近恒等映射的扰动,而不是学习一个新的函数。
- 通过某些层的恒等映射实现了多个模型的集成,而且删除ResNet的部分节点对整个模型的影响很小。
- 因为有恒等映射所以反向传播时总会有梯度回传,缓解了梯度消失。
- 残差结构既不增加参数量也不增加模型复杂度。
Architecture
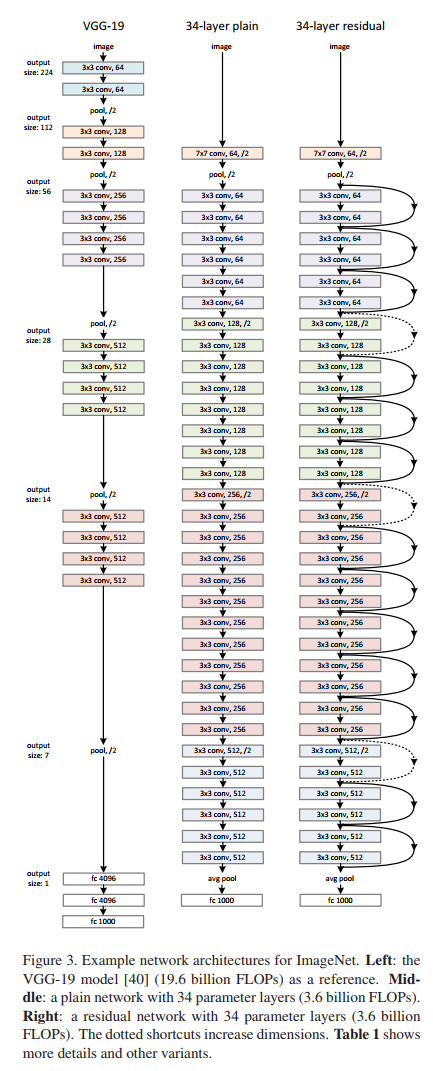
左 VGG-19 中 plain-34 右 residual-34
实线为无需维度匹配 虚线为进行维度匹配
作者仿照VGG堆叠了一个34层的结构(plain)与相同深度的残差结构模型(residual)进行对比。设置plain版本的模型时遵循两条规则:
- 对于相同大小的输出特征图时,每块使用相同数量的滤波器
- 将输出特征图大小减半时,将滤波器数量翻倍
虽然设计的34层比VGG19层数更深但具有更少的滤波器与参数。对应的residual版本在维度匹配时有两个选项:
- 直接进行恒等映射,在输入周围填充0,无额外添加参数
- 使用1×1卷积增加维度
在所有卷积层之后跟有全局池化层,再进入输出1000个神经元的全连接层进行softmax分类。
训练策略
- 优化器:带动量的SGD
- batch size:256
- 学习率:0.1(错误率平稳时除以10)
- 权重衰减:0.0001
- 动量:0.9
- 迭代次数:最大600000
训练时输入图像的224×224是通过水平翻转后随机裁剪出来的,对于每张输入图像减去每个像素的平均值,再使用标准颜色增强。每次卷积后在激活函数前使用批量归一化层(BN)。测试时使用与VGG同样的策略在多尺度取平均得分。
更深的网络 bottleneck
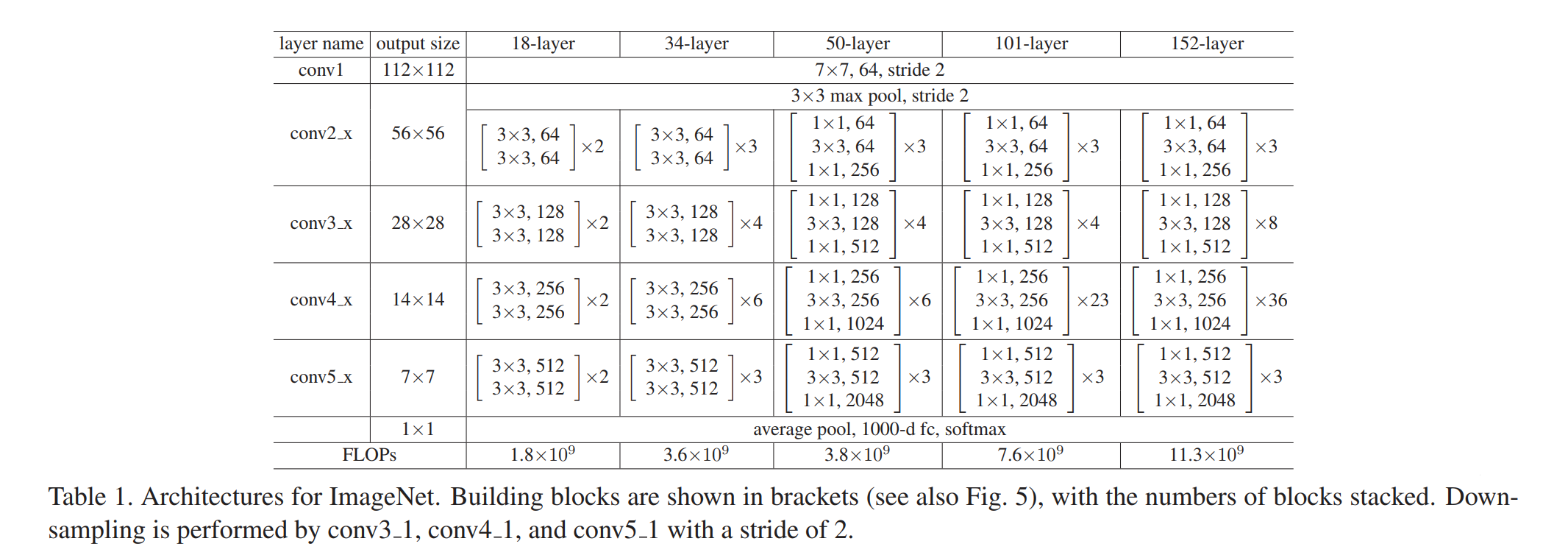
在50、101、152层中使用的残差结构被叫做bottleneck,即前面加一个1×1卷积层降维,后面再加一个1×1卷积层升维,这样做的的目的是减少计算量。
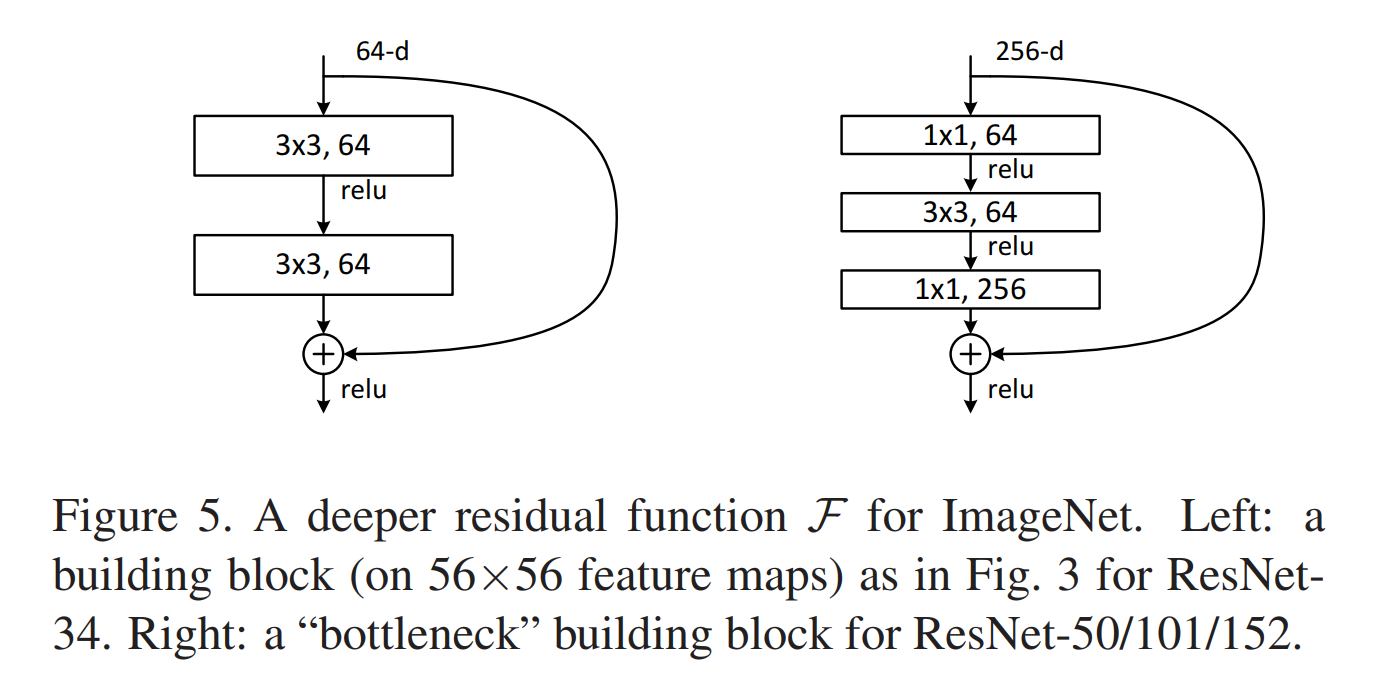
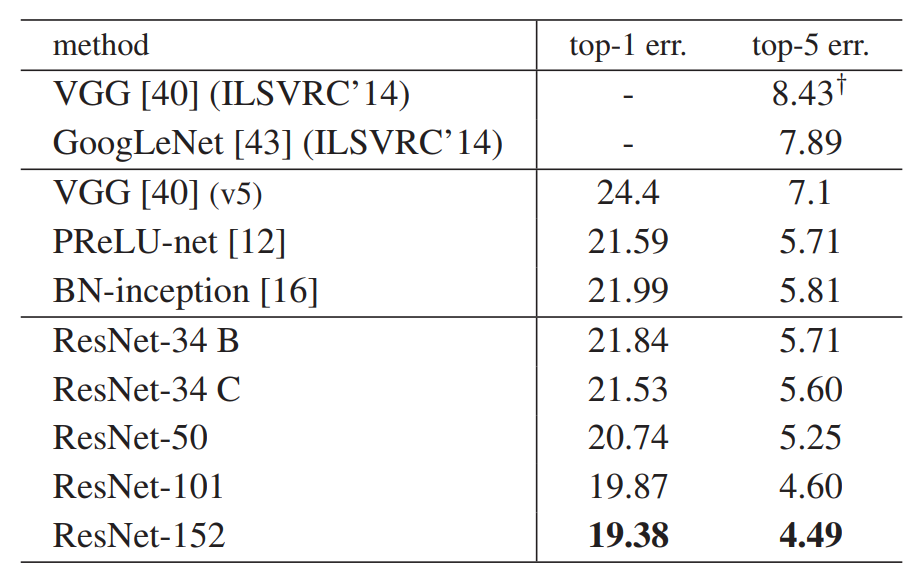 尽管深度显著增加,但152层的ResNet的复杂度仍然小于VGG-16/19。(ResNet-152 11.3亿FLOP、VGG-16/19 15.3/19.6亿FLOP)而且实验结果表明深层ResNet比34层准确率高很多,也没有退化问题可以从深度中获得显著的准确率提升。
尽管深度显著增加,但152层的ResNet的复杂度仍然小于VGG-16/19。(ResNet-152 11.3亿FLOP、VGG-16/19 15.3/19.6亿FLOP)而且实验结果表明深层ResNet比34层准确率高很多,也没有退化问题可以从深度中获得显著的准确率提升。
实验细节
解决网络退化问题
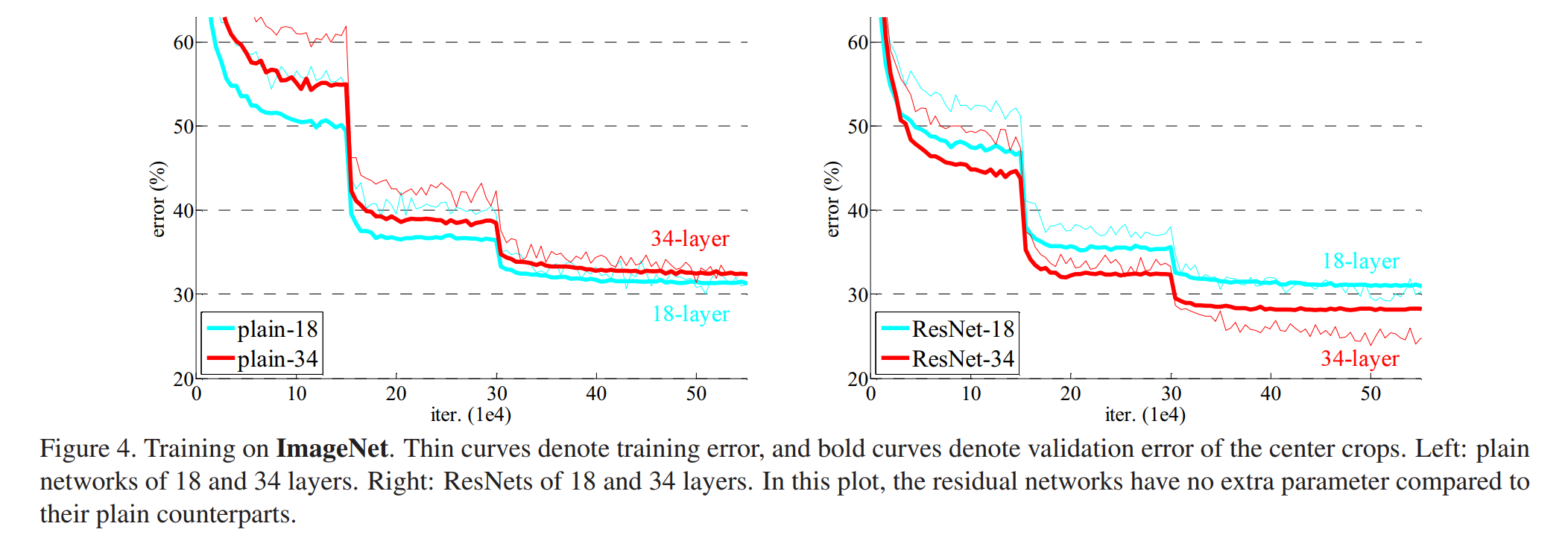
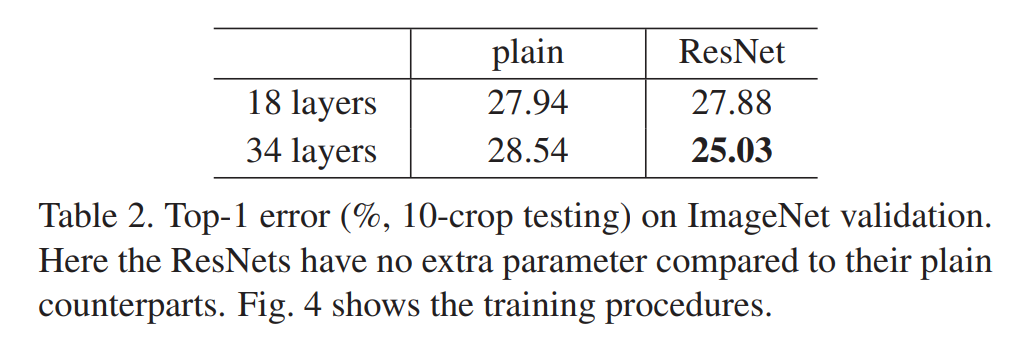
通过上表可以发现从plain-18到plain-34发生了网络退化,且这种问题不是由梯度消失引起的,因为加入的BN层能保证前向传播时方差不为0,同时反向传播时也有良好的梯度传递。在维度匹配时使用填充0的方法,从图中可以看到residual-34比residual-18错误率有明显的下降。可以得出结论,退化问题得到了解决,加深网络提高了准确率。
映射方式
为探究跨层连接时应该只用恒等映射还是加入些非线性层,作者比较了三种映射方式:
- A:升维时在特征图周围填充0
- B:仅为升维的恒等映射使用1×1卷积
- C:为所有恒等映射使用1×1卷积
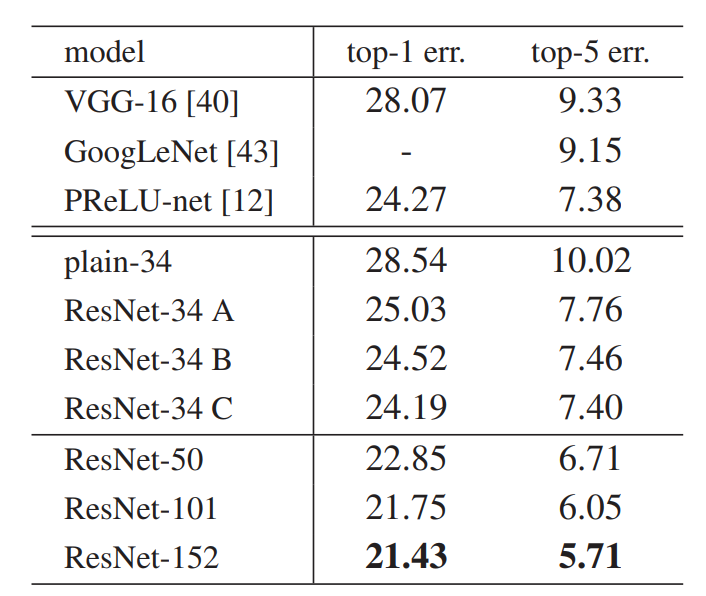
实验结果表明C方法的效果最好,但性能的优异可能是因为多添加的参数。所以出于效率原因在实际使用中还是使用方法B。
其他
- 对于ResNet-110,0.1的学习率过大无法收敛,所以先用0.01的学习率来预热训练,直到训练误差低于80%后再回到0.1来训练。
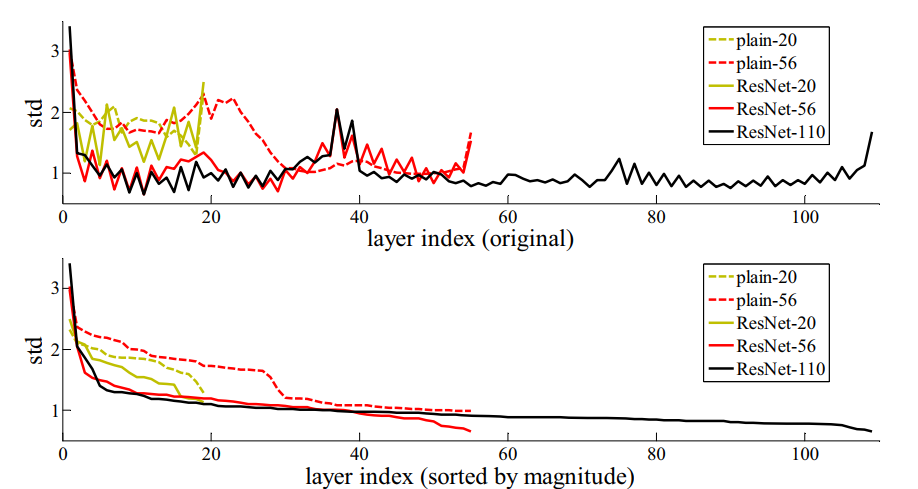
- 如上图所示,通过分析每一层响应值(BN层之后ReLU之前的值)的标准差发现残差函数比非残差函数更接近与0,而且更深的网络有更小的响应幅度。
- 作者还尝试了超过1000层的网络,实验结果表明比ResNet-110错误率略高,可能发生了过拟合。这说明残差结构的网络可以做到非常深也不会发生网络退化问题。