论文pdf
前言
Purpose: 提高网络性能最直接的方法就是增加网络的深度与宽度。但深层的网络容易发生过拟合且计算量太大往往难以训练。通常应对这两个问题的方法是将全连接的架构转换为稀疏连接的架构,但由于在非对称稀疏结构上进行计算效率非常低,所以转换为稀疏矩阵的回报很小。
Method: 作者提出了Inception结构,是将稀疏矩阵转换为相对密集的子矩阵,有文献表明这种结构计算有优异的性能。再由NiN的1×1卷积层解决维度不断增多的问题,减少计算量使模型可以做的更深更大。
Results: 构建密集结构块来逼近一个最优的稀疏结构被证明是一个可行的方案,可以在适度增加计算量的同时显著提高性能。使用Inception结构的GoogLeNet也取得了ILSVRC 2014分类任务的第一名。
GoogLeNet是一个基于Hebbian法则和多尺度处理构建的网络结构,提出了Inception结构块。GoogLeNet共22层,参数数量与ALexNet相比较减少了12倍,但效率有很明显的提升。以6.67%的top-5误差取得了2014年ImageNet挑战赛图像分类的第一名。
随着移动设备与嵌入式计算的不断发展,算法的效率以及对内存的使用率变得越来越重要。而GoogLeNet在结构设计上考虑了这个因素,使得模型可以用于学术界与工业界。
Inception结构中的1×1卷积层从来自于NiN,加入1×1卷积层主要有两个目的:
- 作为特征降维模块,以减少计算量,使模型可以更深更大
- 在增加模型深度、宽度的同时不会显著降低性能
Inception结构设计思路
提高深度神经网络性能最直接的方法是将模型设计的更深、更宽,可这个方案有两个缺点:
- 更大的模型就有更多的参数,就更容易发生过拟合;更大的模型需要更多的数据样本,而高质量的训练集往往很贵
- 要求更高的计算效率,而且更大的网络利用率未必高(会有很多参数输出接近于0)
解决这两个问题的方法是将全连接层与卷积层转换为稀疏连接的架构。但是在非均匀稀疏结构上进行计算的效率非常低,即使减少运算次数,也会在查找与缓存操作上花费大量计算量,以至于切换为稀疏矩阵回报很小。在关于稀疏矩阵计算的大量文献表明将稀疏矩阵聚类为相对密集的子矩阵往往会为稀疏矩阵乘法提供优异的性能,也是由此产生了Inception结构,经过测试在计算机视觉领域取得了成功。
Architecture
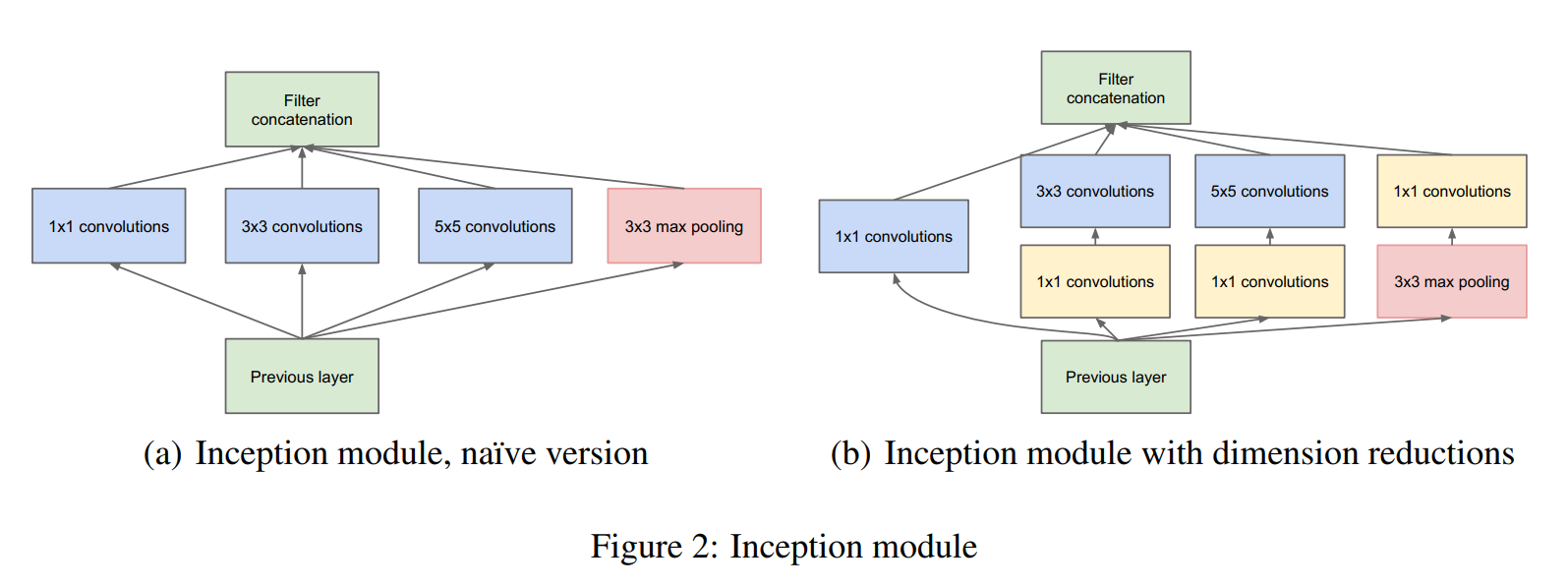
- Inception结构的主要思想就是找到密集结构组件去逼近和替换一个最优的局部稀疏结构,并且因为卷积的平移不变性,使我们可以在空间上不断重复这种密集结构。即增加了网络深度、宽度;减少计算量;稀疏连接的方式还有助于减少过拟合
初始版本 (a)
Arora提出了一种逐层的结构,它对上一层进行相关统计分析,并将高相关性的单元聚类在一起组成下一层。假设下层的单元都与输入图像的某些区域相关,且这些单元都分布在滤波器组中,而在接近输入的层中相关单元会在一个区域中大量聚集。这样很多聚类关注的是同一个区域,在下一层中可以通过1×1卷积覆盖。在更高层聚类越来越大数量越来越少,所以可以通过更大的卷积来覆盖更大的聚类。为了方便对齐,仅使用1×1、3×3、5×5的卷积核。Inception将这些层的结果合并到一起,输出到下一层中,此外添加了池化层提升效果。
关于合并结果:假设上一层输出为28×28×192,则:
| 1×1卷积核 | 3×3卷积核 | 5×5卷积核 | 3×3池化层 | 合并 | |
|---|---|---|---|---|---|
| 卷积核 | 1×1×64 | 3×3×128 | 5×5×32 | 3×3 | |
| padding | 0 | 1 | 2 | 1 | |
| stride | 1 | 1 | 1 | 1 | |
| 输出 | 28×28×64 | 28×28×128 | 28×28×32 | 28×28×192 | 28×28×416 |
但是初始版本中的池化层输入与输出维度相同,再进行合并后会导致输出越来越大,进而导致后续Inception结构中计算量很大。
改进版本 (b)
由于输出维度的问题,采用1×1的卷积核来进行降维,分别加在3×3、5×5卷积层的前面,池化层的后面。这样做不仅可以减少输出维度、减少计算量,还可以通过1×1卷积层的激活函数增加网络非线性的判别能力。改进后的Inception结构如(b)所示。
Inception结构的特点
- 采用不同大小的卷积核意味着不同大小的感受野,等同于进行不同尺度的特征融合
- 卷积核采用1×1、3×3、5×5方便对齐,设置步长为1,分别设定填充为0、1、2后即可得到相同维度的特征
- 可以增加网络深度、宽度,而计算量不会增加太多,比具有非Inception架构的类似网络快2-3倍
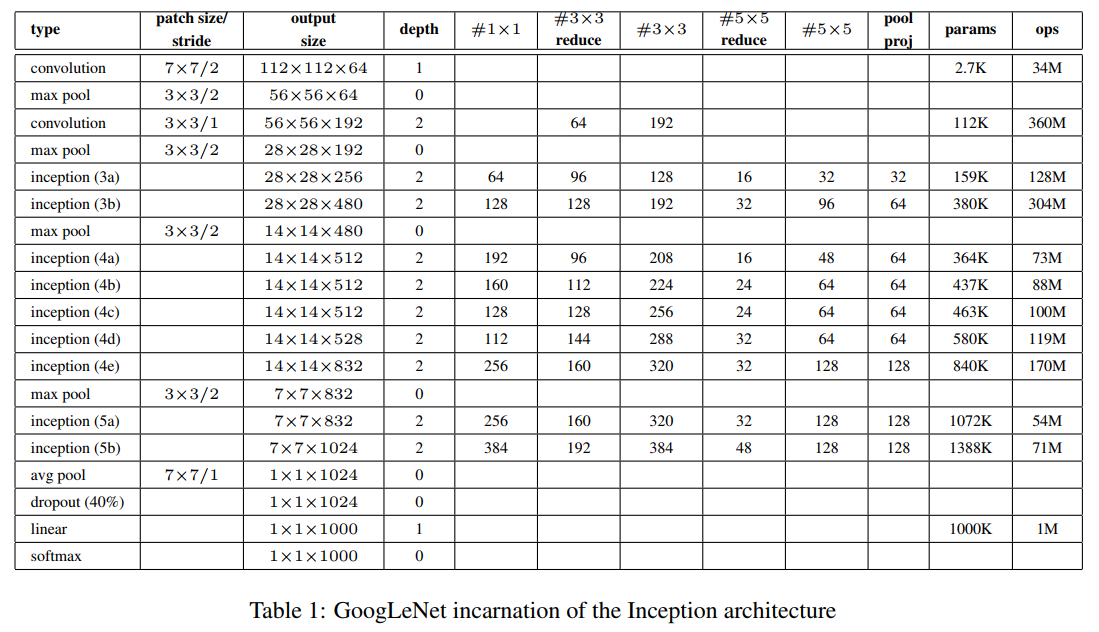
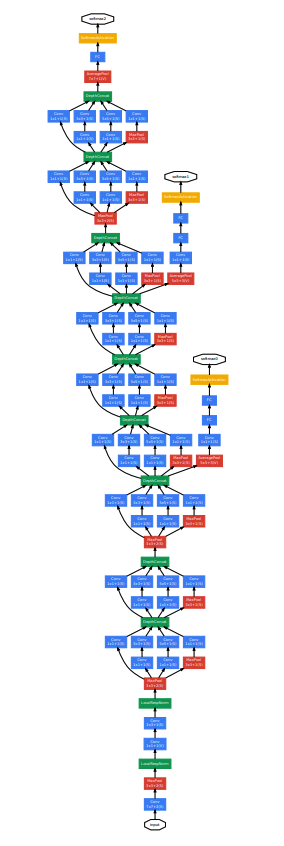
GoogLeNet
- GoogLeNet致敬LeNet :D
- 所有卷积层中激活函数均使用ReLU函数
- 输入图像大小为224×224×3,并减去RGB通道均值
- 网络包含22层(算上池化层为27层),独立层块的层大概有100个
- 加入辅助分类器,用于增加较低层网络的分类能力,防止梯度消失,增加正则化
辅助分类器
相对较浅的的网络在此分类任务上的优异表现说明网络中间的层提取的特征也具有很强的辨别力,所以添加连接到中间层的辅助分类器。这些分类器反向传播梯度,并具有额外的正则化。在训练期间,它们的损失以一定的权重加入到总损失当中(权重为0.3)。在测试时,不使用辅助分类器。
辅助分类器具有:
- 一个大小为5×5步长为3平均池化层
- 用于降维的128个1×1卷积
- 全连接层有1024个神经元
- 全连接层的Dropout比例为0.7
- softmax作为分类
训练策略
- 优化器:SGD
- momentum :0.9
- weight decay : 每8个epoch下降4%
- 多尺度采样:从8%到100%随机选择大小,3/4与4/3之间选择比例
- 光度失真防止过拟合
- 从双线性、面积、最近邻和三次、等概率中随机选择插值方法
ILSVRC 2014分类任务
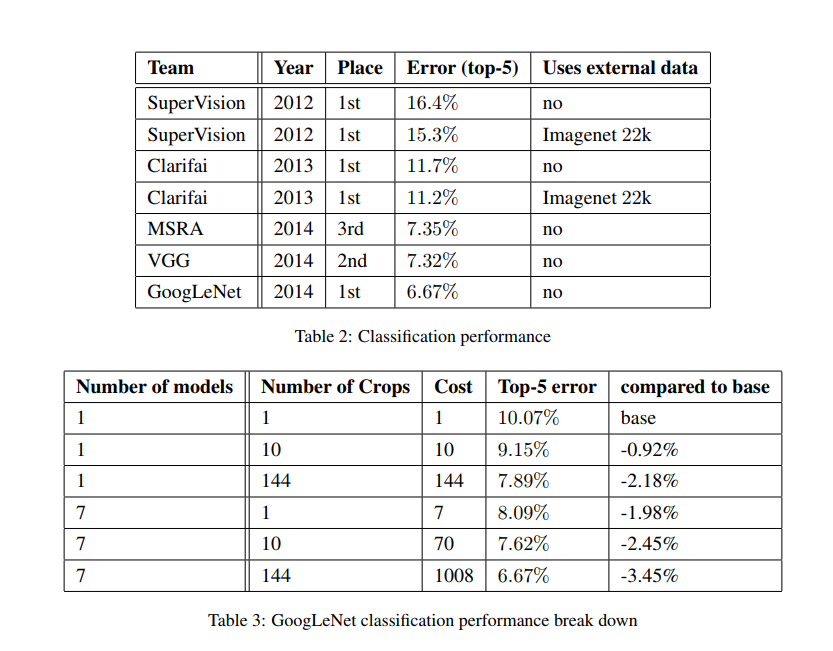
- 训练没有使用外部的数据
- 独立训练7个版本的GoogLeNet,并进行模型融合。7个版本使用相同的初始化与学习策略,仅在采样方式上有区别
- 进行预测时,将输入图像缩放到短边为256、288、320、352的四个尺度,再从上面裁剪出三个正方形(上中下或左中右),对于每个正方形取四个角落与中心和原图像共6张图片缩放到224×224,最后将这些图片与这些图片的镜面翻转输入到网络中。(总图片数为4×3×6×2=144)
- 多张裁剪图片与多个模型预测的softmax结果取平均值作为最后的预测结果
ILSVRC 2014检测任务