论文pdf
前言
Purpose: 主要研究了深度对模型性能的影响。
Method: 设置对照实验,深度加深、通道数增多。
Results: 深度对分类精度是有利的。
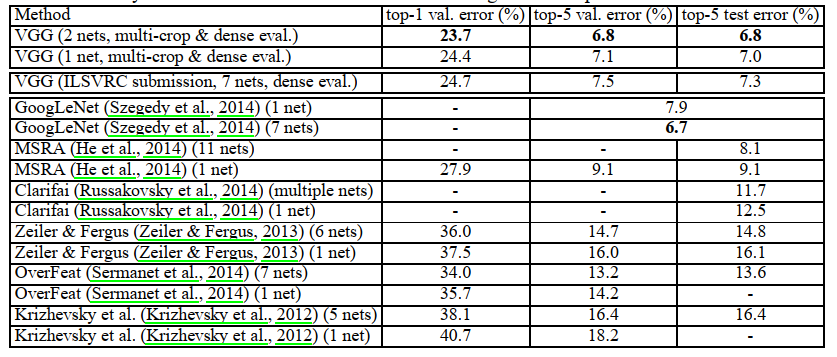
VGG的模型与传统的CNN模型没有太大的区别,主要对具有3×3的卷积滤波器架构进行了研究,探究深度对模型的影响, 发现将模型加深到16-19层时效率有显著的提高。并获得2014年ImageNet挑战赛图像分类的第二名(第一名为GoogLeNet)。
- 卷积核(kernels):二维的矩阵
- 滤波器(filters):多个卷积核组成的三维矩阵,多出的一维是通道(channel)
- 特征图 (feature map) :卷积层提取到的特征,即多个二维图堆叠在一起即为一个特征图
Tricks
- 使用小卷积核(主要为3×3,少部分1×1)
- 网络层数更深,通道数更多
- 池化核大小设置为2×2
- 训练深层网络时(16、19层VGG)使用前面模型的参数来进行参数初始化
- 网络测试时将三个全连接层替换为3个卷积层
Architecture
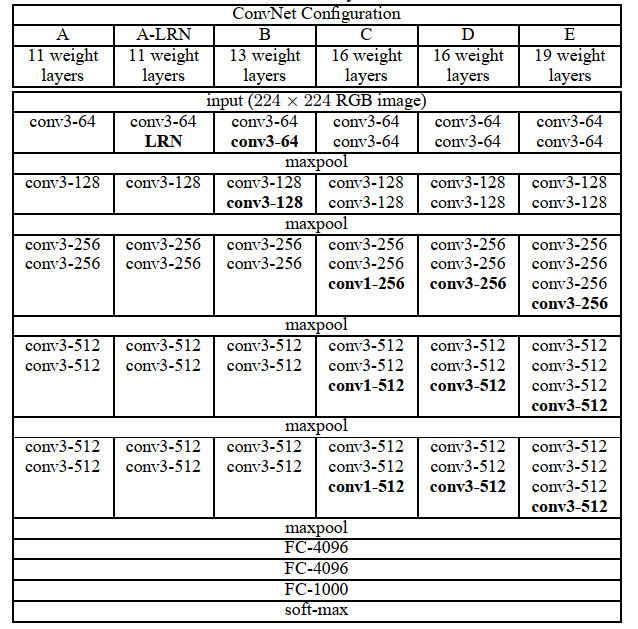
实验共分为六组层数由11层加深到19层(层数仅包括卷积层与全连接层),通道数由64扩大至512,但因为使用的卷积核均为1×1、3×3的小卷积核,即使网络很深参数量也不会很大。每个卷积层后跟有ReLU激活函数,池化层使用的是大小为2×2,步长为2的最大池化。
曾在ALexNet中使用的局部响应归一化层,该层会对相邻的N个通道在同一像素位置处的像素值进行归一化(normalize)。通过上图比较A与A-LRN发现准确率没有提升,还花费了更多计算资源。所以在接下来的实验中均没有使用LRN层。
VGG中只使用了1×1、3×3的卷积核,使用小卷积核的理由是两个3×3的卷积堆叠与一个5×5的卷积获得的感受野大小相同,同理三个3×3的卷积堆叠与一个7×7的卷积获得的感受野大小相同。此外堆叠多个小卷积核替代大卷积核还有如下优势:
- 由一个激活函数增加到三个,使决策函数更具有判别能力。
- 卷积层滤波器参数减少,三层3×3卷积核的参数个数为3×(C×C×3×3)=27C^2,一层7×7卷积核的参数个数为C×C×7×7=49C^2。还使用1×1的卷积核对输入通道数进行线性变换,1×1卷积核可以在不影响感受野的情况下增加非线性判别(跟在卷积层后的激活函数)。
- 小卷积核替代大卷积核有正则化的作用,堆叠的小卷积核是将大卷积核提取到的特征进行了分解。
Feture map 变化
| 层数 | 大小 | 通道数 |
|---|---|---|
| 1 | 224×224 | 3 |
| 2 | 112×112 | 64 |
| 3 | 56×56 | 128 |
| 4 | 28×28 | 256 |
| 5 | 14×14 | 512 |
| 6 | 7×7 | 512 |
随着特征图由一开始的224×224×3到最后的7×7×512,通过卷积、池化操作将特征从图片的相对位置分摊到channel上,再通过全连接层将特征压缩为稠密的feature map,最后给到softmax进行分类。
训练(TRAINING)
超参数
- 优化器:带动量的SGD
- batch size:256
- 学习率:0.01
- momentum:0.9
- weight decay:5×10^-4
- dropout rate(前两个全连接层):0.5
- 迭代次数:74 epochs
训练图像尺寸
模型接受的输入图像大小为224×224,输入到模型中的图像为经过缩放(rescale)后随机裁剪(crop)得到的。即使为同一张图片,在每一轮epoch的训练中裁剪出的图片也是不一样的。而且在裁剪后的图上还进行了水平翻转与随机RGB通道值改变。设定训练尺度S为图像缩放后的短边,但因为裁剪的大小固定为224×224,所以S不小于224。当S等于224时,因为长边大于等于224,裁剪出的图像可以基本捕获整个图像;当S远大于224时,只会裁剪出图像的一部分或某些物体的一部分。论文中使用两种方法设置S值。
- 固定训练尺度S值,用单一尺度去训练。论文中使用256、384两种单一尺度曲训练,先用S=256去训练网络,之后再用S=384去微调(fine-tune)图像
- 使用多种尺度训练。给定训练尺度S一个范围(在论文中为[256,512]),每次训练随机采样一个S值。这样做是把要分类的物体缩放到不同的的尺寸,相当于是训练同一模型时是基于不同尺度的图像进行的,即尺度增广(scale jittering)。
测试(TESTING)
测试阶段先对输入图像缩放到预设尺度Q,测试图像的尺寸Q与训练图像的尺度S不必一样。且有多个不同的测试尺度Q可以得到更好的性能。
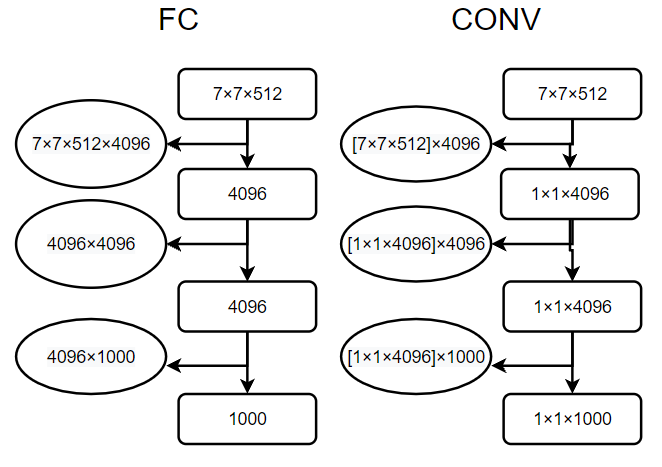
将全连接层转换为卷积层
Namely, the fully-connected layers are first converted to convolutional layers (the first FC layer to a 7 × 7 conv. layer, the last two FC layers to 1 × 1 conv. layers).
在测试阶段作者将三个全连接层依次转换为7×7、1×1、1×1的卷积层。现在整个网络没有了全连接层,网络中的特征图不再固定,所以模型可以处理任意大小的输入。因为卷积操作与全连接不同,卷积核的参数数量,也就是卷积核的大小,它与前一层的特征图尺寸是没有关系的;但是全连接层的参数是随着前一层特征图的大小变化而变化的,当输入图像大小不同,全连接层输入的特征图大小也不一样,那么全连接层的参数数量就不能确定,所以采用全连接层的网络必须固定输入图像的大小,而替换为卷积层后就实现了对输入图像尺寸限制的突破。如下图所示:
分类试验
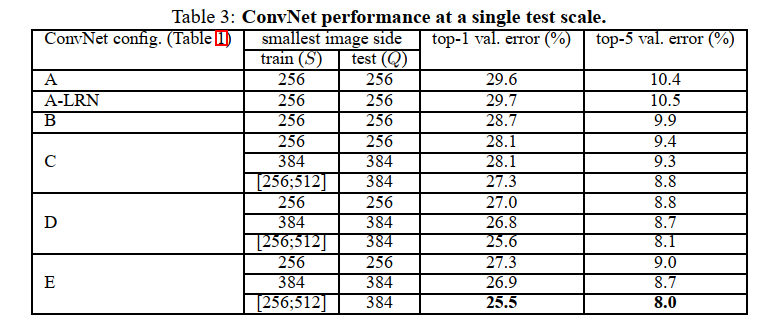
单尺度评估
当固定训练尺度S时,测试尺度Q等于训练尺度S;当使用多种尺度训练时,即训练尺度介于[Smin,Smax]时,测试尺度Q等于0.5*(Smin+Smax)。
实验结论
- LRN层对于分类性能没有提高
- 深度增加,分类性能提高
- 多尺度训练比固定尺度训练效果要好
多尺度评估
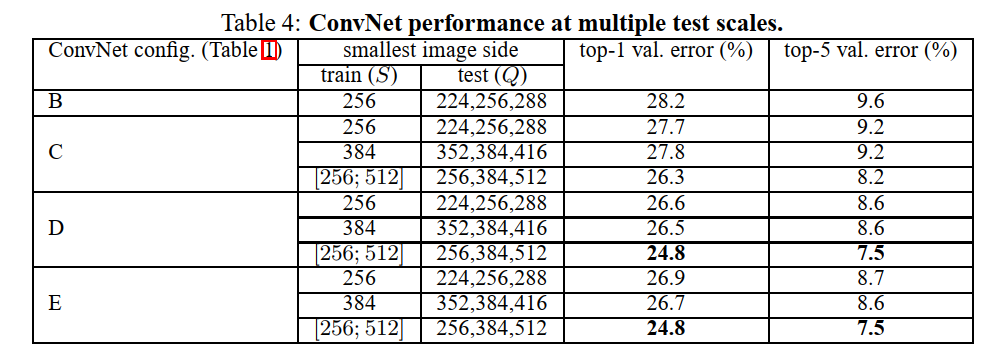
当固定训练尺度S时,测试尺度Q等于{S-32, S, S+32};当使用多种尺度训练时,即训练尺度介于[Smin,Smax]时,测试尺度Q等于{Smin, 0.5*(Smin + Smax), Smax}。
实验结论
- 测试时使用多尺度测试,会有更好的效果,且模型越深效果越好。
多crop评估
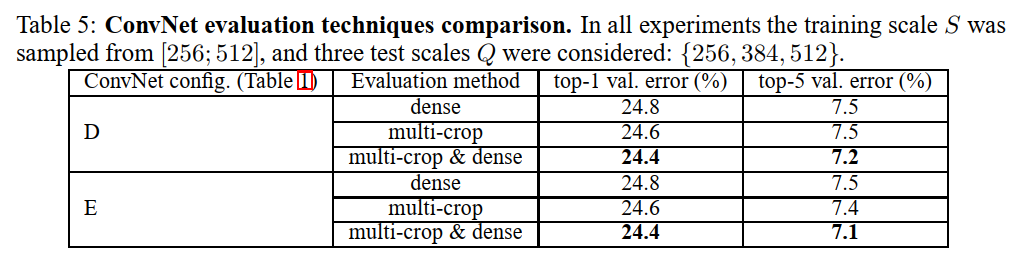
- dense evaluations:为使用卷积层替代全连接层,最终输出为w×h×n,其中n为分类类别数。对每个类别的w×h个值进行求和,即为对某个类别的概率
- multi-crop evaluations:为通常的卷积层加全连接层,通过将测试图片缩放到不同大小的测试尺度Q,再从Q×Q的图像上裁剪出多个S×S的图像,对这些图像进行测试,得到多个1×n的向量(其中n为分类类别数)。通过对这些向量的每一维求平均,最后得到n类分类概率。
dense 因为不限制图像的大小,只使用卷积与池化可以提取到像素点与周围像素点的信息,增大了感受野,因此提高了分类的效率。而multi-crop 需要从图片上进行裁剪再输入进网络,增加了一定的噪声。而且将两者结合起来效果会更好。
多模型融合

- 多模型融合是基于多个网络softmax输出的结果的平均,取得了比单模型更好的成绩。