论文pdf
前言
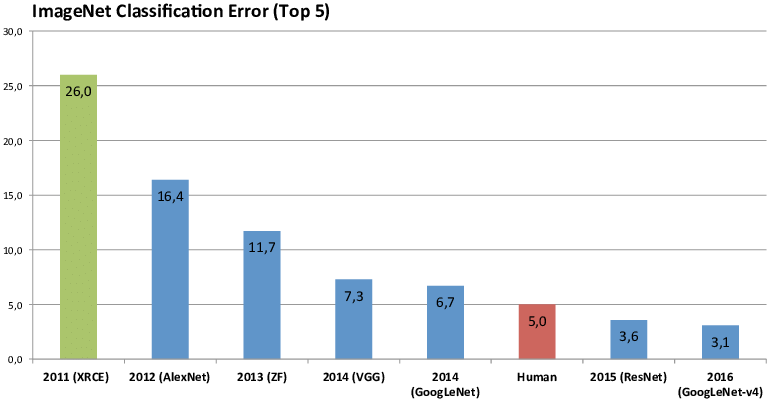 ALexNet是2012年 ImageNet 2012 图像识别挑战赛的冠军,并且Top-5错误率到达了15.3%,比第二名低了10.8个百分点。
ALexNet是2012年 ImageNet 2012 图像识别挑战赛的冠军,并且Top-5错误率到达了15.3%,比第二名低了10.8个百分点。
本来在1998年LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气。但是因为缺少大量带有标签的数据、硬件计算速度很慢,
所以在上世纪90年代到2012年的大部分时间里,卷积神经网络并不比其他机器学习方法优秀(如支持向量机)。
在2009年,ImageNet数据集发布,并发起ImageNet挑战赛:要求研究人员从100万个样本中训练模型,以区分1000个不同类别的对象。ImageNet数据集由斯坦福教授李飞飞小组的研究人员开发,利用谷歌图像搜索(Google Image Search)对每一类图像进行预筛选,并利用亚马逊众包(Amazon Mechanical Turk)来标注每张图片的相关类别。且随着硬件的不断迭代,计算速度有了很大的提高。随着ALexNet的横空出世,引起了深度学习的热潮。
Tricks
ReLU 激活函数
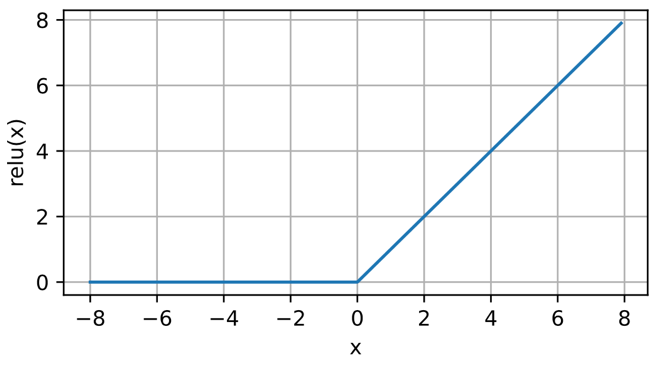
ReLU全称Rectified Linear Unit,即纠正线性单元。比起sigmoid、tanh激活函数,ReLU函数有如下的优点:
- ReLU函数计算量小,运算速度快
- ReLU函数是非饱和函数非线性,不易发生梯度消失
- ReLU使部分神经元输出为0,减少参数间的相互依赖关系,从而缓解过拟合现象,加快收敛
函数的饱和性
右饱和:当x趋向于正无穷时,函数的导数趋近于0,此时称为右饱和。
左饱和:当x趋向于负无穷时,函数的导数趋近于0,此时称为左饱和。
饱和函数和非饱和函数:当一个函数既满足右饱和,又满足左饱和,则称为饱和函数,否则称为非饱和函数。
GPU 并行计算
ALex使用了两个GTX 580 3GB GPU进行并行计算,将网络分布在两个GPU上。我笔记本只有cpu:(
GPU能够直接读取和写入彼此的内存而无需经过cpu内存。所以并行计算方案是每个GPU上有一半的神经元,且在某些层中进行通信。 例如:第三层的神经元从两个GPU的所有神经元上获取输入;而第四层的神经元仅从处于同一GPU的神经元上获取输入。
This means that, for example, the kernels of layer 3 take input from all kernel maps in layer 2. However, kernels in layer 4 take input only from those kernel maps in layer 3 which reside on the same GPU.
重叠池化层
s为步长,z×z为池化核的大小(在ALexNet之前没有步长的概念)
传统池化:s=z 即池化不重叠
重叠池化:s<z 即池化重叠
且这种方案降低错误率,降低过拟合。
This scheme reduces the top-1 and top-5 error rates by 0.4% and 0.3%, respectively, as compared with the non-overlapping scheme s = 2; z = 2, which produces output of equivalent dimensions. We generally observe during training that models with overlapping pooling find it slightly more difficult to overfit.
数据增强
图像增广在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。 此外,应用图像增广的原因是,随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。ALexNet采用如下两种图像增广方法:
- 图像平移与水平翻转
- 改变图像RGB通道的值
图像平移与水平翻转
训练时,从256×256的图像中截取224×224的图像,且对每张图像进行水平翻转。使训练集扩大2048倍,从而减少过拟合。
预测时,截取5个224×224的图像(4个角与中心)及其水平翻转图像,共10张图像进行softmax预测取平均值作为最后的预测结果。
改变图像RGB通道的值
对整个ImageNet训练集的RGB通道值进行主成分分析,每张图片改变的幅度为其相应的特征值乘以从均值为零和标准偏差为0.1的高斯分布中提取的随机变量成正比。该方法利用了改变亮度与颜色不会改变识别的物体身份。
其中α为随机变量,p为特征向量,λ为特征值。
Dropout层
随机挑选全连接层中的一些结点(ALexNet中为0.5)将他们的输出设为0,被丢弃的神经元不在这一轮训练中参与前向传播与反向传播。 这使得神经元不能过度依赖上一层中的任意一个神经元,被迫学习与其他神经元的许多不同随机子集。也就是在每一轮在训练不同结构的模型,提高了模型整体的鲁棒性。
Architecture
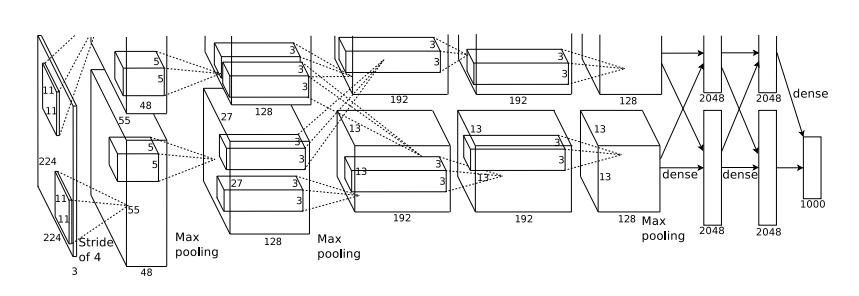
整个网络包含五个卷积层与三个全连接层,最后一层全连接层输出由softmax产生1000个类别的概率。其中第三个卷积层的神经元连接到第二层的所有神经元上,第二、四、五个卷积层的神经元连接到同一GPU的神经元上,全连接层连接到前一层的所有神经元上。响应归一化层连接在第一、二个卷积层之后(因为响应归一化层后面就没有使用了,这里就没研究,而且公式好复杂:(),第一、二、五个卷积层后有重叠池化层,五个卷积层与三个全连接层后均有ReLU激活函数。
第一层输入大小为224×224×3,采用96个大小为11×11×3的卷积核,步长为4,填充为2。输出大小为55×55×96。
采用3×3池化核,步长为2的最大池化层,得到的第一层输出为27×27×96。
第二层采用256个大小为5×5×48的卷积核,步长为1,填充为2。输出大小为27×27×256。
采用同样的池化层,得到第二层的输出为13×13×256。
第三层采用384个大小为3×3×256的卷积核,步长为1,填充为1。第三层输出大小13×13×384。
第四层采用384个大小为3×3×384的卷积核,步长为1,填充为2。第四层输出大小为13×13×384。
第五层采用256个大小为3×3×384的卷积核,步长为1,填充为2。输出大小为13×13×256。
采用同样的池化层,得到第五层的输出为6×6×256。
之后再连接上两个带Dropout的有4096个神经元的全连接层。
最后再连接上有1000个神经元的全连接层作为最后的预测。
卷积层输出计算公式
改变输出图像大小
n为输入图像大小,k为卷积核大小,p为填充大小,s为步长
改变输出通道
输入图像
卷积核
输出图像